# 流程动态参与者
流程动态参与者是由流程服务在流程运行时,通过调用业务应用实现的获取动态参与者的接口,动态获取参与者列表。
低代码应用已经内置实现了获取动态参与者的接口,内部是通过调用函数编排的方式来实现的。
基于编排的动态参与者,可以在流程运行时动态指定参与者,包括用户、角色和部门。
# 应用配置
为了让流程服务能够调用业务应用的动态参与者接口,首先需要将业务应用的服务地址注册到流程服务的应用设置中。
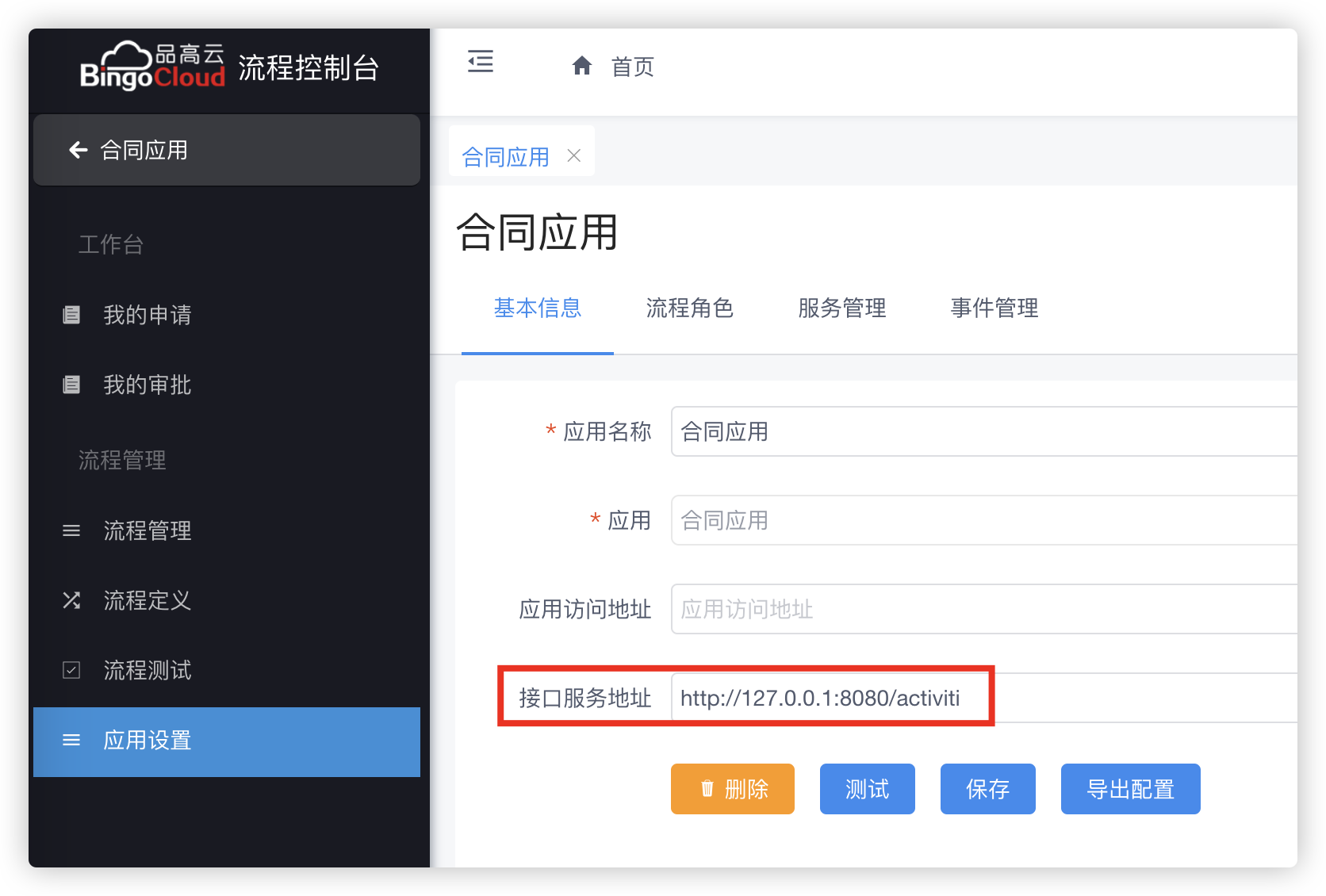
# 动态用户
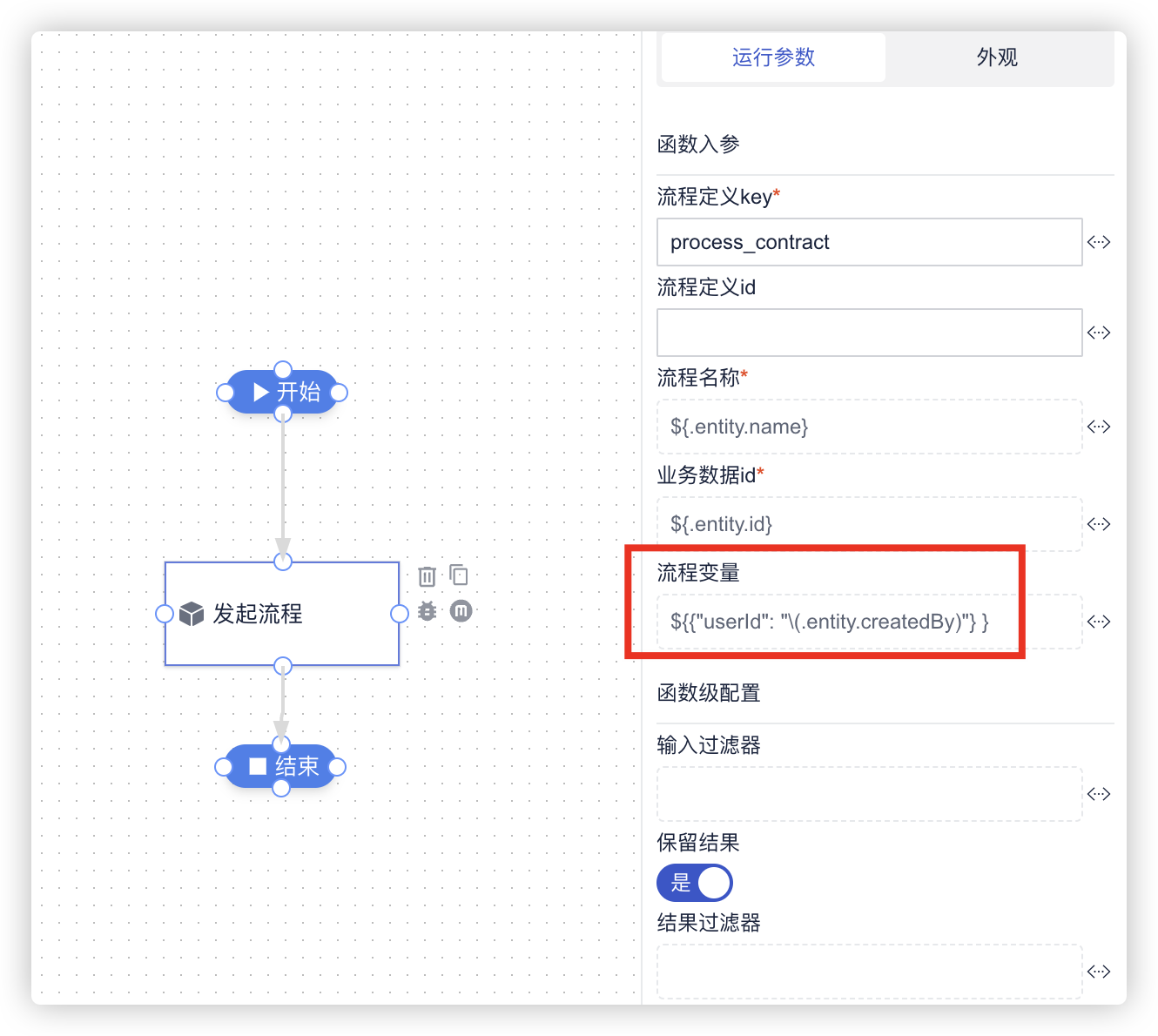
# 1 设置流程变量(可选项)
如果后续的函数编排需要根据一些业务数据来计算动态参与者,可以在发起流程的时候预先设置流程变量。
下图演示了设置动态变量的方式,变量名为userId,值是通过jq表达式取实体的createdBy字段值。
# 2 创建函数编排
# 2.1 使用系统编排节点
例如我们建一个获取申请者上级用户的函数编排
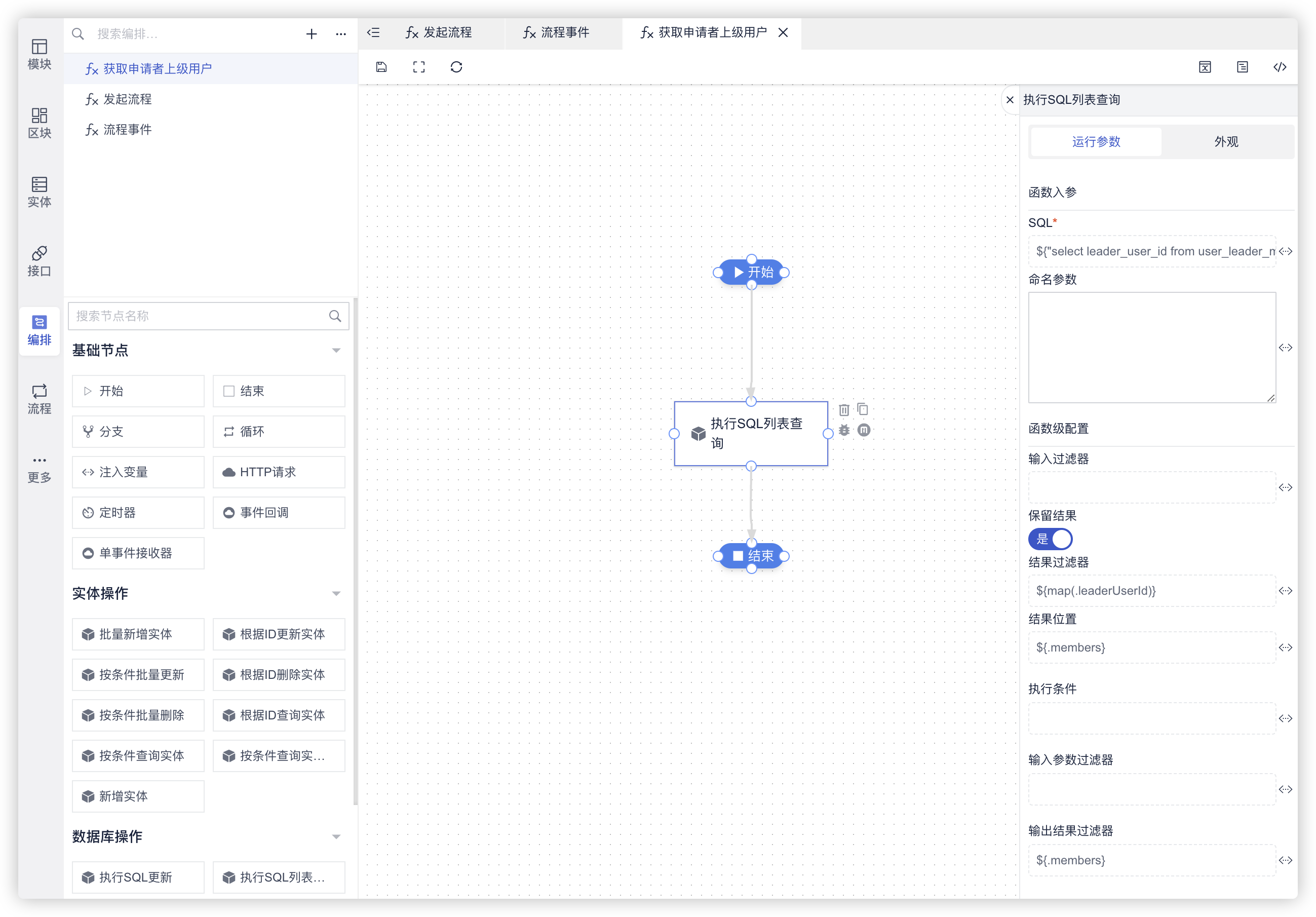
示例中,我们是通过执行SQL列表查询节点来获取申请者上级用户:
"select leader_user_id from user_leader_mapping where user_id = '" + .processVariables.userId.value + "'"
在编排函数中可以使用上下文参数,例如上图通过.processVariables.userId.value获取了前文设置的流程变量。
以下是上下文参数样例:
{
"processInstance": { // 流程实例
"id": "c808f1c5-344d-11ef-8dff-8ab4c0be40c6",
"name": "测试合同",
"processDefinitionId": "process_contract:51:59eea6d2-3438-11ef-8dff-8ab4c0be40c6",
"initiator": "eZGHAryQLmpd8sZXXnFpnZ",
"startDate": "2024-06-27T14:23:34.493+08:00",
"businessKey": "8fff26b4-3846-4614-88be-ea6cfbdd7649",
"status": "RUNNING"
},
"processVariables": { // 流程级别变量
"userId": {
"name": "userId",
"type": "string",
"processInstanceId": "c808f1c5-344d-11ef-8dff-8ab4c0be40c6",
"value": "eZGHAryQLmpd8sZXXnFpnZ",
"taskVariable": false
},
"oauthAppId": {
"name": "oauthAppId",
"type": "string",
"processInstanceId": "c808f1c5-344d-11ef-8dff-8ab4c0be40c6",
"value": "Ieeh3W4LvOAHDQHBMMC5lD",
"taskVariable": false
},
"workflowClientChannelDestination": {
"name": "workflowClientChannelDestination",
"type": "string",
"processInstanceId": "c808f1c5-344d-11ef-8dff-8ab4c0be40c6",
"value": "Ieeh3W4LvOAHDQHBMMC5lD.OyF4wA",
"taskVariable": false
}
},
"taskVariables": { // 任务级别变量
"cd90f4e2-344d-11ef-8dff-8ab4c0be40c6": {}
},
"currentTask": { // 当前环节任务
"id": "cd90f4e2-344d-11ef-8dff-8ab4c0be40c6",
"name": "财务审批",
"status": "CREATED",
"createdDate": "2024-06-27T14:23:43.773+08:00",
"priority": 50,
"processDefinitionId": "process_contract:51:59eea6d2-3438-11ef-8dff-8ab4c0be40c6",
"processInstanceId": "c808f1c5-344d-11ef-8dff-8ab4c0be40c6",
"taskDefKey": "Activity_1py6ztp"
}
}
以上样例采用的是通过sql列表查询的方式,实际应用开发中可以设计任意类型的编排函数,只要最终返回的结果是一个包含用户ID的数组,即编排最终的运行返回结果类似:
["userId1","userId2", ...]
上图示例中设置了结果过滤器、结果位置、输出结果过滤器,就是为了最终返回一个用户ID数组。
# 2.2 使用扩展编排节点
如果动态用户的计算逻辑很复杂,系统编排节点不能很好的满足业务需求,还可以用自定义 Java 代码的方式处理,通过扩展编排节点来调用自定义的 Java 代码。参考扩展编排节点章节。
以下示例演示了如何通过Java代码扩展编排节点,并使用扩展节点创建编排。
public class DemoBean {
private final Dao dao;
public DemoBean(Dao dao) {
this.dao = dao;
}
@FunctionModule(label = "查询动态用户", operation = "@demo.find(id)", name = "DemoFind", group = "流程")
@FunctionOutput(name = "result", label = "结果")
public List<String> find(@FunctionParameter(label = "用户ID", required = false, type = DataType.STRING) String id) {
return dao.createSQLQuery("select leader_user_id from user_leader_mapping where user_id = ?", id).list()
.stream()
.map(map -> map.getString("leaderUserId"))
.collect(Collectors.toList());
}
}
@Configuration(proxyBeanMethods = false)
@FunctionScan(basePackages = {"com.lowcode.webapp.orchestration"})
public class OrchestrationConfiguration {
@Bean
@ExpressionModule("demo")
DemoBean demo(Dao dao) {
return new DemoBean(dao);
}
}
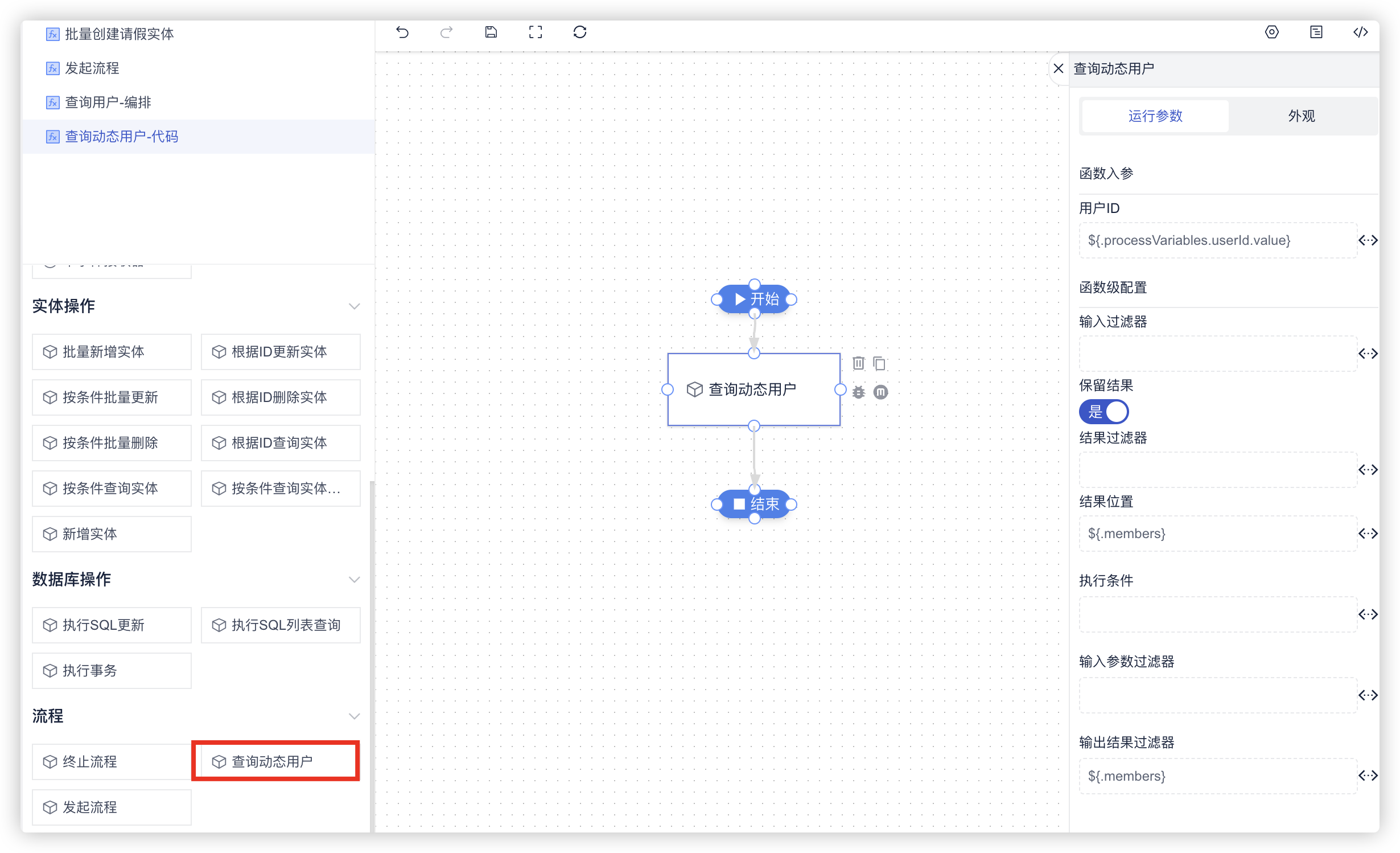
需要注意的是,在查询动态用户的编排中,需要配置结果位置、输出结果过滤器,目的是为了排除中间过程参数,保证最终返回的结果是一个包含用户ID的数组。
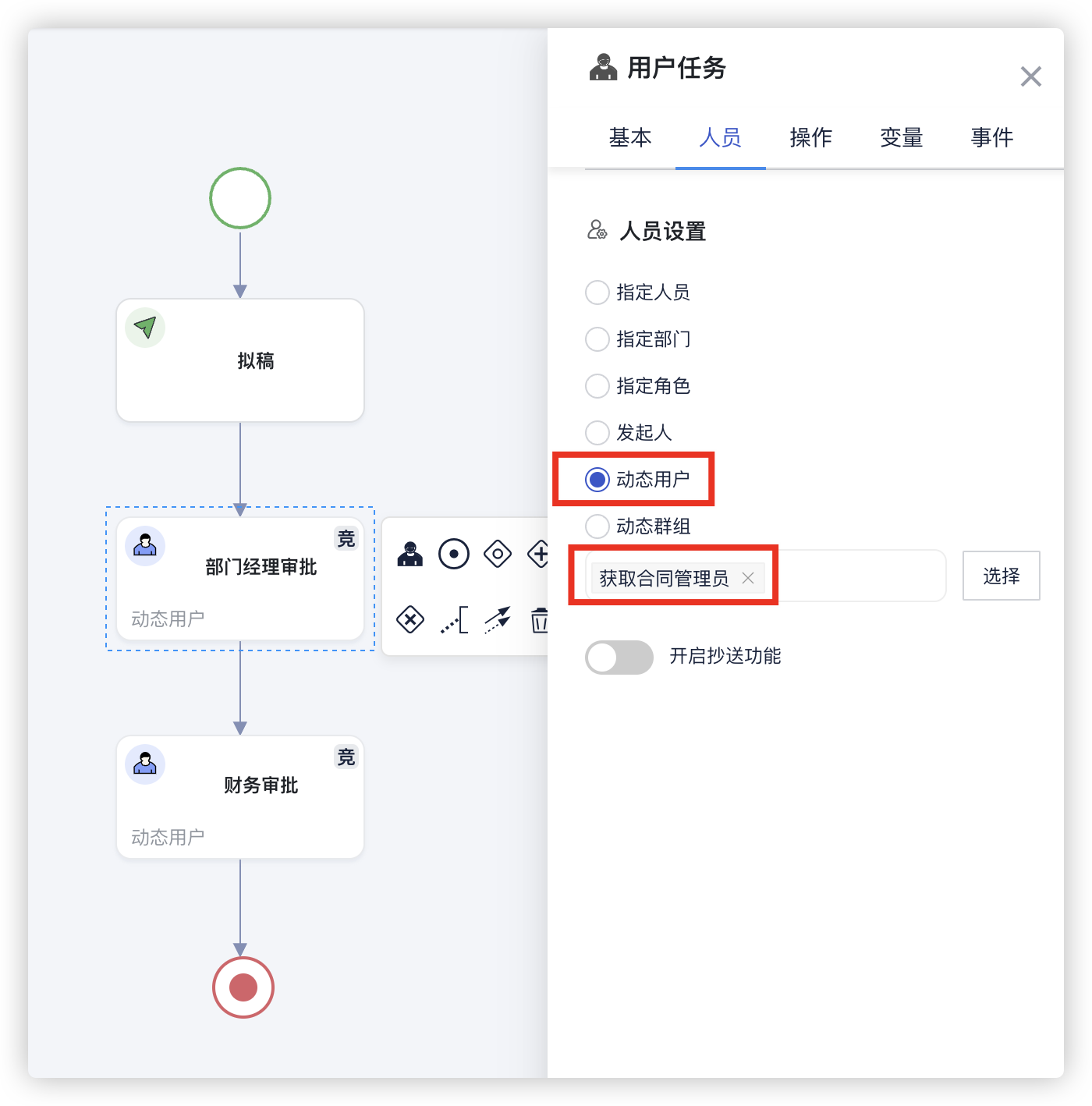
# 3 选择编排
在流程的环节,选择人员为动态用户,选择函数编排获取项目管理员作为动态用户的计算方式
# 动态群组
动态群组包含动态角色和部门,和动态用户使用方式一样,只是人员选择为动态群组,函数编排返回的结果数据类型如下所示即可:
[{
"type": "group",
"id": "roleId1"
}, {
"type": "group",
"id": "roleId2"
}, {
"type": "group",
"id": "orgId1"
}, {
"type": "group",
"id": "orgId2"
}, ...]